TP Sémantiques d’écritures et de lectures
Le présent TP est conçu pour être un mini projet. Son objet est de pouvoir affiner votre compréhension des sémantiques de production/consommation. Il vous permettra de mettre en oeuvre l’écriture de producteurs et de consommateurs.
Vous allez choisir un thème de production d’information/messages. Dans les précédents TP le thème était la mesure de la température de l’air pour des villes. Vous pouvez reprendre ce thème, le compléter ou bien en choisir un autre.
Vous devez réaliser par vous même les tâches suivantes. Vous utiliserez le langage python dans l’écriture des programmes à réaliser. Pensez à encapsuler tout cela dans des “venv” avec un requierement.txt afin qu’on puisse reproduire vos développements.
Bien entendu vous devrez utiliser ou concevoir un docker-compose.yml mettant en oeuvre au minimum 3 brokers, un outil de visualisation simple des topics/brokers.
Pour ce TP, j’ai choisi de produire et consommer des métriques hardware de l’ordinateur hôte (CPU, mémoire, utilisation du disque, etc.).
1) Création de topic :
- Créer un topic (RF 3, Partions 5) par le moyen de votre choix.
- Expliquez votre docker-compose.
- Montrez et expliquez votre choix de méthode de création du topic.
- Citez d’autres méthodes pour faire la même chose.
- Que vont vous permettre ces choix : “RF=3, nombre de partitions=5” ?
- Qu’est-ce que l’ISR ?
- Qu’est-ce que le min.insync.replicas ?
- Quelle est sa valeur par défaut ?
- Quelles sont les bonnes pratiques pour le définir ?
- Où peut-on le définir ? (niveau broker, niveau topic, niveau producteur) ?
Explication du docker-compose
- Trois brokers Kafka Confluent en mode KRaft**
- Un container
topic-init- s’exécute après le démarrage des brokers
- crée automatiquement ton topic
- permet de reproduire l’environnement facilement
- Kafdrop
Méthode de création du topic
Bootstrap via un container dédié
Résultat :
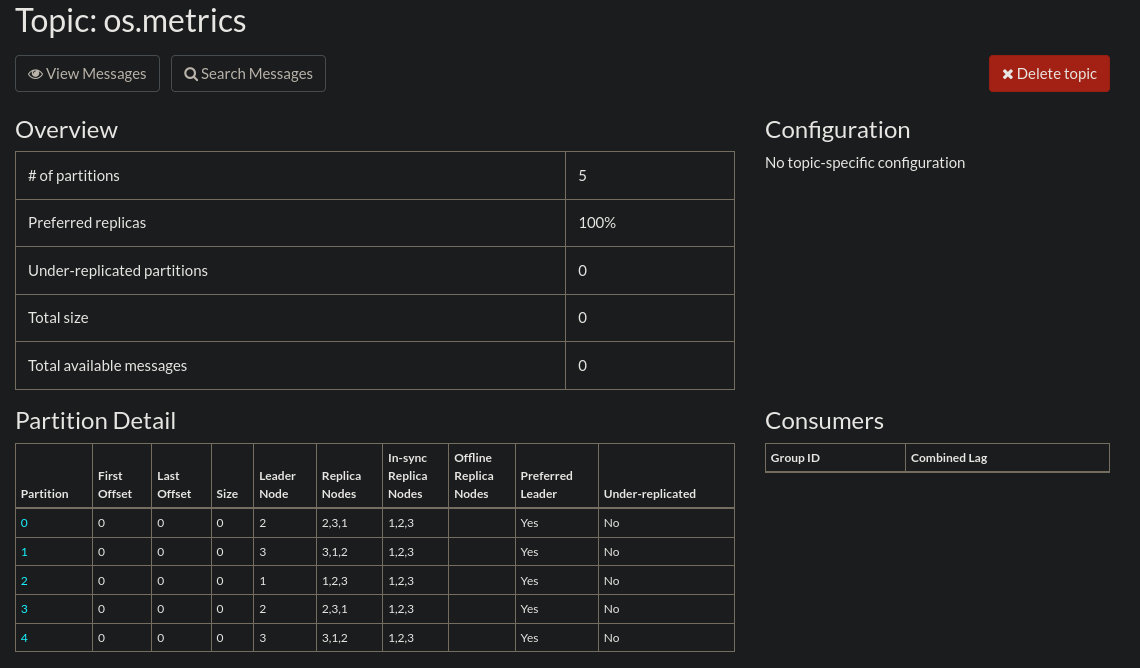
Autres méthodes pour créer un topic
- Via CLI depuis un container Kafka
- Via l’API Admin Kafka
- Création automatique par le producteur
Que permettent les choix RF=3 et partitions=5 ?
RF = 3 (Replication Factor)
- Chaque partition possède 3 copies
- Tolérance de panne : tu peux perdre 1 broker sans perte de données
- Écriture possible en configuration
min.insync.replicas=2
5 partitions
- parallélisme pour la consommation
- débit plus élevé (plusieurs partitions permettent plusieurs fetch threads)
- load-balancing automatique entre les brokers
Qu’est-ce que l’ISR ?
ISR = In-Sync Replicas C’est l’ensemble des réplicas synchronisés avec la partition leader.
Qu’est-ce que min.insync.replicas ?
C’est le nombre minimum de réplicas dans l’ISR exigés pour accepter une écriture.
Valeur par défaut
min.insync.replicas = 1
Bonnes pratiques
| Cluster | min ISR recommandé |
|---|---|
| 1 broker | 1 |
| 3 brokers | 2 |
| 5 brokers | 3 |
Où peut-on le définir ?
- Broker :
KAFKA_MIN_INSYNC_REPLICAS=2 - Topic : via
--config min.insync.replicas=2 - Producteur : via
acks=all+request.required.acks=-1
2) Réaliser un producteur avec les différents types d’écriture :
- Définissez ce que sont les différents types d’écriture.
- Quels sont les avantages et inconvénients de chaque type d’écriture.
- Ecrivez un producteur réalisant “At most one” et expliquez les risques de pertes de messages.
- Ecrivez un producteur réalisant “At least one” et expliquez les risques de doublons.
- Ecrivez un producteur réalisant “Exactly one” et expliquez comment vous vous y êtes pris pour garantir cette sémantique.
Définissez les différents types d’écriture
Kafka propose trois types de garanties de livraison des messages :
- At Most Once (AMO) pas d’acks, pas de retry, le plus rapide mais le moins fiable.
- At Least Once (ALO) acks=all + retries, garantit que le message n’est jamais perdu mais peut être dupliqué.
- Exactly Once (EOS) Idempotence, Transactions, Aucun doublon, aucune perte
Avantages et inconvénients de chaque écriture
| Mode | Avantages | Inconvénients | Cas d’usage |
|---|---|---|---|
| At Most Once | Très rapide, faible overhead | Perte potentielle de messages | Logs faibles valeur, télémétrie volumineuse |
| At Least Once | Aucun message perdu | Doublons possibles (par retries) | Monitoring, finance, traitements critiques |
| Exactly Once | Aucune perte + aucun doublon | Plus lent ; plus complexe ; transactions nécessaires | Paiements, IoT critique, pipelines ETL |
Producteur At Most Once
producer = KafkaProducer(
bootstrap_servers=["kafka-1:9092"],
acks=0, # Pas d’ack
retries=0, # Pas de retry
)Risques de pertes :
- Si le message ne peut pas être écrit sur le broker (crash, perte réseau, partition indisponible),
Kafka ne le renverra jamais. - Le producteur considère le message comme envoyé, même s’il n’a jamais atteint Kafka.
- Le buffer interne peut être perdu en cas de crash de l’application. Performances maximales, mais non fiable.
Producteur At Least Once
producer = KafkaProducer(
bootstrap_servers=["kafka1:9092"],
acks="all", # Tous les réplicas ISR doivent confirmer
retries=5, # Retry si échec → risque doublons
)Risques de doublons
- Le producteur n’a pas de réponse (timeout),
→ il renvoie le message,
→ mais le message initial avait été écrit. - Un leader change pendant l’écriture.
- Le broker confirme trop tard.
Fiable (pas de perte), mais désambiguïsation nécessaire côté consumer
Producteur Exactly Once
producer = KafkaProducer(
bootstrap_servers=["kafka1:9092"],
enable_idempotence=True, # Active l'idempotence Kafka
acks="all",
retries=5,
transactional_id="os-metrics-producer-1",
)
producer.init_transactions()
producer.begin_transaction()
producer.send("os.metrics", json.dumps(metrics).encode())
producer.commit_transaction()1. Idempotence
- Kafka attribue un Producer ID (PID) et un Sequence number à chaque message.
- Si le message est réémis (retry) → Kafka détecte le doublon et le rejette. Pas de doublons.
2. Transactions Kafka
Garantissent qu’un batch de messages est :
- soit écrit entièrement,
- soit pas du tout.
Cela évite :
- les écritures partielles,
- les incohérences en cas de crash,
- les doublons après un commit partiel.
3) Réaliser un consommateur
- At most once.
- At least once.
- Exactly once. Aidez vous de “enable.idempotence=true, acks=all”
- Faites en sorte que vos consommateurs puissent faire varier facilement leurs vitesses de consommation (par exemple en ajoutant un Thread.sleep dans la boucle de consommation).
At Most Once
consumer = KafkaConsumer(
"os.metrics",
bootstrap_servers=["kafka-1:9092"],
enable_auto_commit=False,
auto_offset_reset="latest"
)- no auto-commit
- offset = latest → saute tous les messages anciens (perte potentielle)
At Least Once
consumer = KafkaConsumer(
"os.metrics",
bootstrap_servers=["kafka-1:9092"],
enable_auto_commit=True,
auto_commit_interval_ms=1000,
auto_offset_reset="earliest"
)Exactly Once
producer = KafkaProducer(
bootstrap_servers=["kafka-1:9092"],
enable_idempotence=True,
acks="all",
retries=5,
transactional_id="metrics-consumer-tx-1"
)
producer.init_transactions()Puis :
producer.begin_transaction()
...
producer.send_offsets_to_transaction(...)
producer.commit_transaction()Faire varier la vitesse des consommateurs
CONSUMPTION_DELAY = 2
time.sleep(CONSUMPTION_DELAY)Mise en place d’une variable d’environnement modifiable dans docker-compose.yml :
CONSUMPTION_DELAY = os.getenv("CONSUMPTION_DELAY")4) Réaliser un groupe de consommateurs
- Créez un groupe de consommateurs avec 3 consommateurs.
- consommateur1 : vitesse de lecture 1 message par 3 secondes
- consommateur2 : vitesse 1 pour 5 secondes
- consommateur3 : vitesse 1 pour 9 secondes
- Observez et expliquez les lags de consommation.
Création du groupe de consommateurs
metrics-consumer-1:
build: ./consumer
container_name: consumer-1
depends_on:
- kafka-1
environment:
CONSUMPTION_DELAY: 3
networks:
- kafka-net
metrics-consumer-2:
build: ./consumer
container_name: consumer-2
depends_on:
- kafka-1
environment:
CONSUMPTION_DELAY: 5
networks:
- kafka-net
metrics-consumer-3:
build: ./consumer
container_name: consumer-3
depends_on:
- kafka-1
environment:
CONSUMPTION_DELAY: 9
networks:
- kafka-netObservation et explication des lags
Le lag = nombre de messages dans une partition qui n’ont pas encore été consommés par le consumer group.
- Consumer 1 (3s) traite rapidement ses partitions → lag faible.
- Consumer 2 (5s) traite plus lentement → lag moyen.
- Consumer 3 (9s) est le plus lent → lag élevé dans ses partitions.
- Comme nous avons 5 partitions et 3 consommateurs :
- Certains consommateurs auront 2 partitions, d’autres 1 partition.
- Les partitions assignées au consommateur le plus lent accumulent beaucoup de backlog.
5) Scénario de panne
- faites un script bash qui arrête aléatoirement un des brokers toutes les 60 secondes.
- Observez et expliquez le comportement de vos producteurs et consommateurs.
#!/bin/bash
BROKERS=(kafka-1 kafka-2 kafka-3)
while true; do
RANDOM_BROKER=${BROKERS[$RANDOM % ${#BROKERS[@]}]}
echo "Arrêt du broker: $RANDOM_BROKER"
docker stop $RANDOM_BROKER
sleep 40
echo "Redémarrage du broker: $RANDOM_BROKER"
docker start $RANDOM_BROKER
sleep 60
doneExemple de sortie de ce script
Arrêt du broker: kafka-2
kafka-2
Redémarrage du broker: kafka-2
kafka-2
Arrêt du broker: kafka-3
kafka-3
Redémarrage du broker: kafka-3
kafka-3
Producteurs
- At Most Once : risques élevés de perte de messages si le broker ciblé est leader d’une partition.
- At Least Once : messages éventuellement dupliqués lors de retries si le leader crash.
- Exactly Once : Kafka tentera de compléter la transaction ; si le broker leader tombe, la transaction échouera et sera relancée → aucun doublon ni perte (EOS robust).
Consommateurs
- Les partitions du broker arrêté seront réassignées à d’autres brokers si possible.
- Lag temporaire pour les partitions dont le leader est indisponible.
- Les consumers continuent de consommer les partitions disponibles.
6) Optionnel si vous avez envie
- Faites en sorte que votre producteur puisse écrire dans un topic avec un schéma Avro.
- Faites en sorte que votre consommateur puisse lire dans un topic avec un schéma Avro.
- Faites en sorte que votre producteur puisse écrire dans un topic avec un schéma JSON Schema.
- Faites en sorte que votre consommateur puisse lire dans un topic avec un schéma JSON Schema.
- Faites en sorte que votre producteur puisse écrire dans un topic avec un schéma Protobuf.
- Faites en sorte que votre consommateur puisse lire dans un topic avec un schéma Protobuf.
- Faites en sorte que votre producteur puisse écrire dans un topic avec un schéma Avro, JSON Schema et Protobuf.
- Faites en sorte que votre consommateur puisse lire dans un topic avec un schéma Avro, JSON Schema et Protobuf.